.svg)
Introducing Arbis AI: The Power of Agentic AI in Exposure Management
Human-only security operations can’t keep pace with modern attack surfaces anymore.




Hive Pro Arbis AI turns exposure data into exposure reduction with action and automation. Analysts no longer have to manually slice and dice data to investigate the exposure. The exposure data when correlated with intelligence from threat and business both, turns into action autonomously and drives exposure reduction.
Built on an agentic architecture with MCP support and BYOLLM flexibility, Arbis is designed with autonomous multi-agent security operations.
.png)
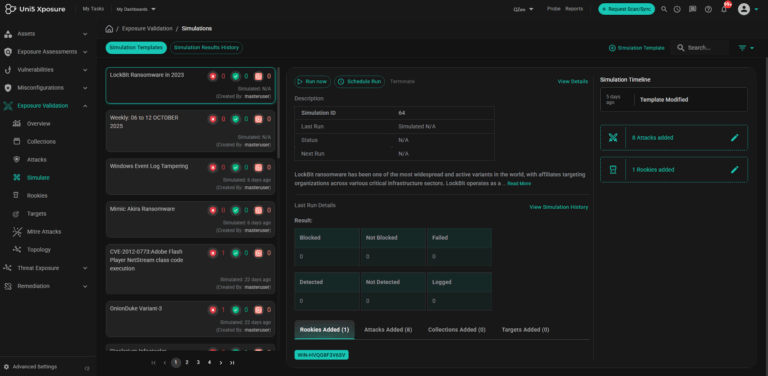


 ARBIS ON THE HIVE PRO PLATFORM
ARBIS ON THE HIVE PRO PLATFORM1
Which imminent threats should I fix today?
Hive Pro maps your exposed assets to active threat actor campaigns in real time. The platform surfaces top imminent threats ranked by exploitability and business impact—so your team knows exactly what to patch first, today.
2
How many EDRs have been bypassed by attacks?
Hive Pro runs continuous adversarial simulations against your entire EDR stack, revealing exactly which attack paths bypass your controls. Get a real-time count of bypassed defenses and the specific TTPs responsible—no guessing, no blind spots.
3
Top 3 actions to fix the exposures today?
Hive Pro AI generates a prioritized fix list: (1) Patch CVEs actively exploited by threat actors targeting your industry, (2) Remediate identity and access misconfigurations that enable lateral movement, (3) Tune EDR signatures to detect the specific TTPs your adversaries use. Each action includes owner assignment and effort estimates.
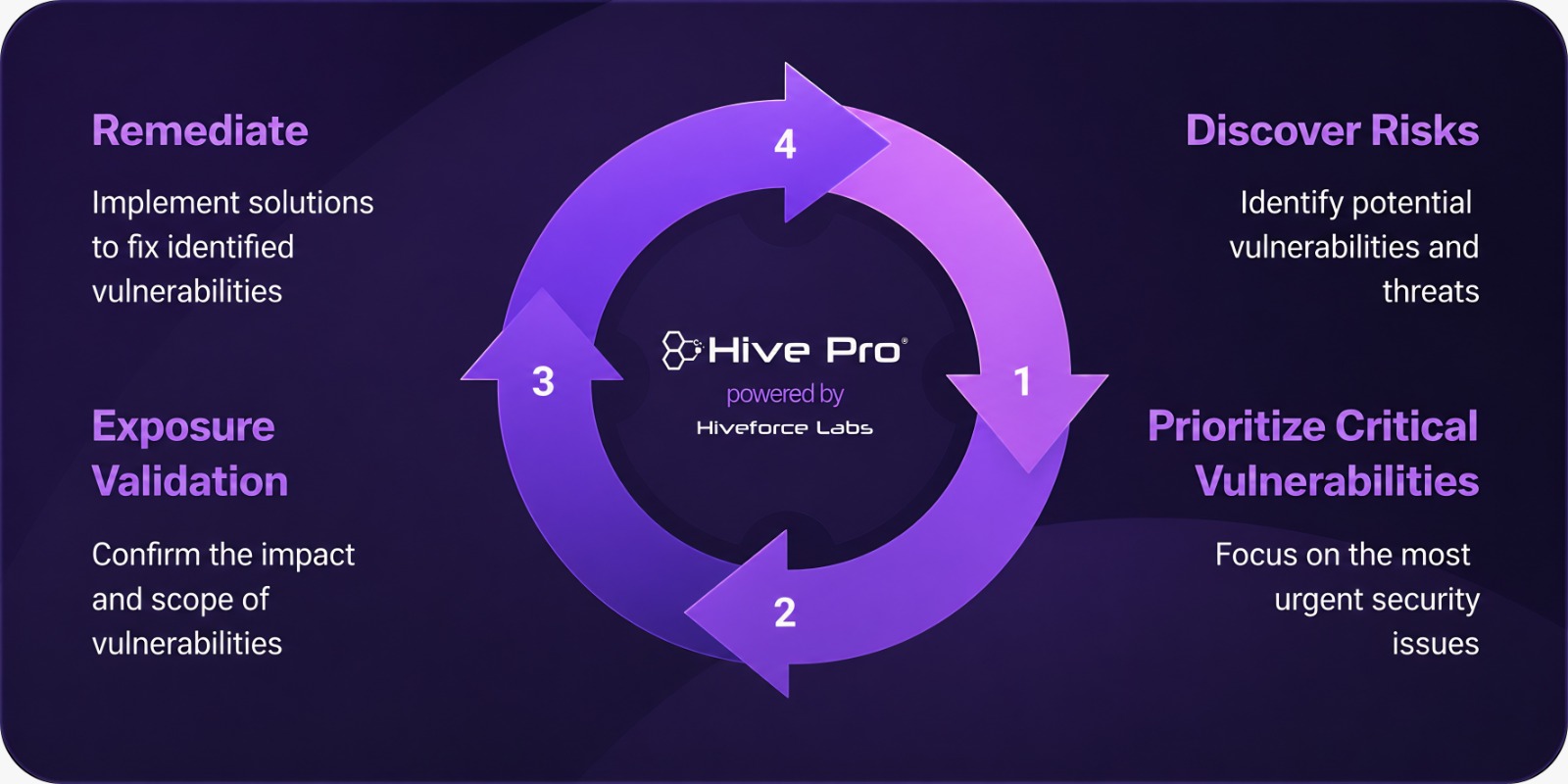
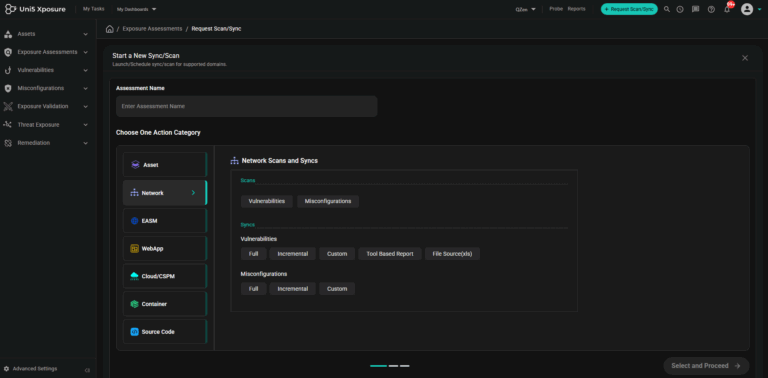
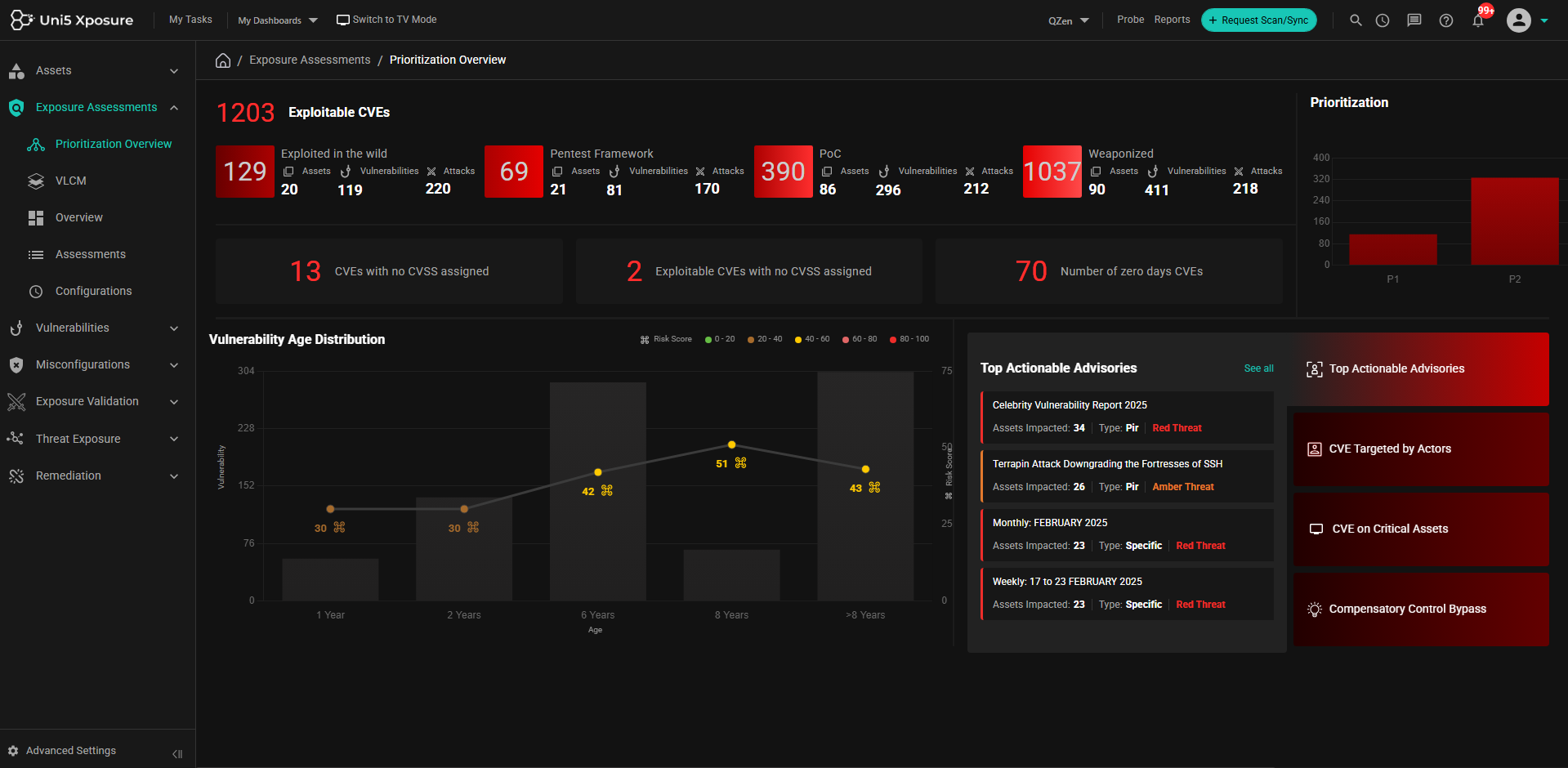
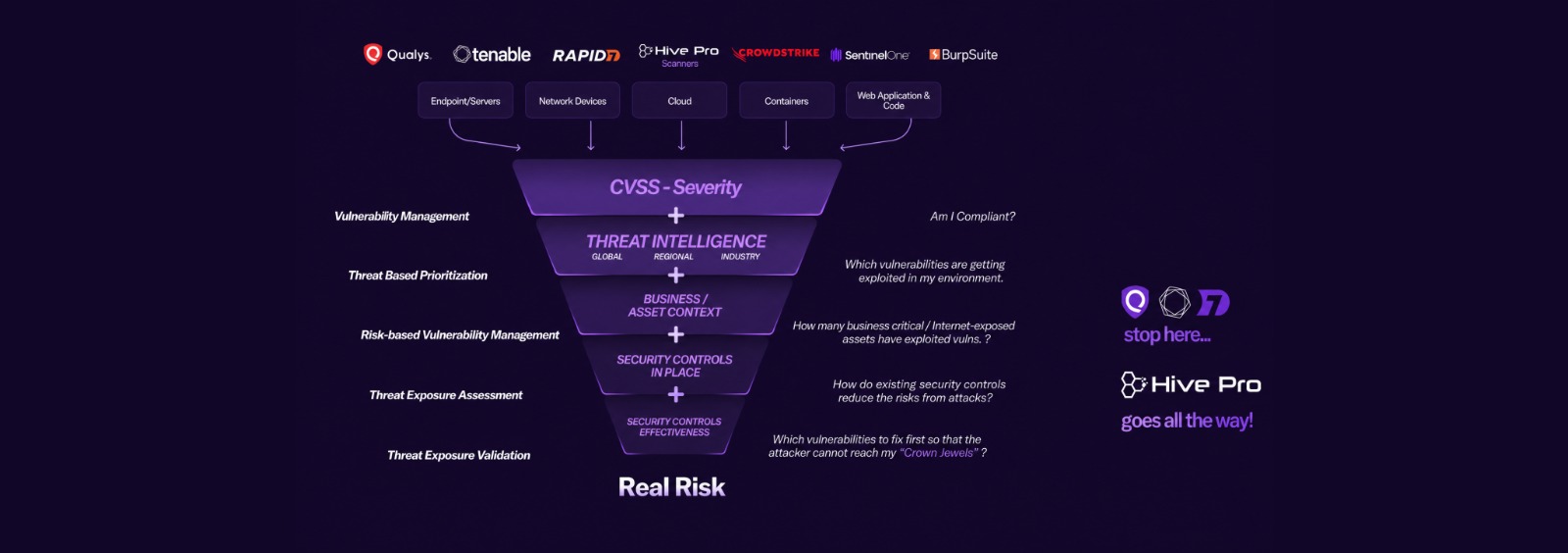
Discover assets, vulnerabilities, misconfigurations from code to cloud without logging into multiple individual platforms. With Hive Pro platform, scans can be orchestrated across Qualys, Tenable, Rapid7, Burpsuite, etc and the results are ingested, de-duplicated, normalized and correlated automatically.
.webp)
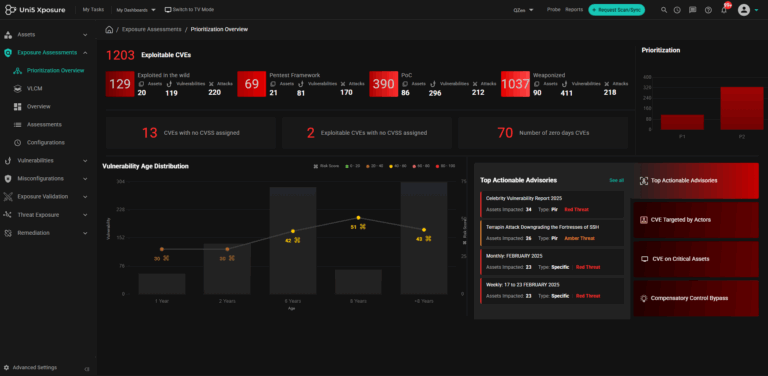
Easy and dynamic prioritization of vulnerabilities based on risk and exposure context. Focus on what matters most to your business.
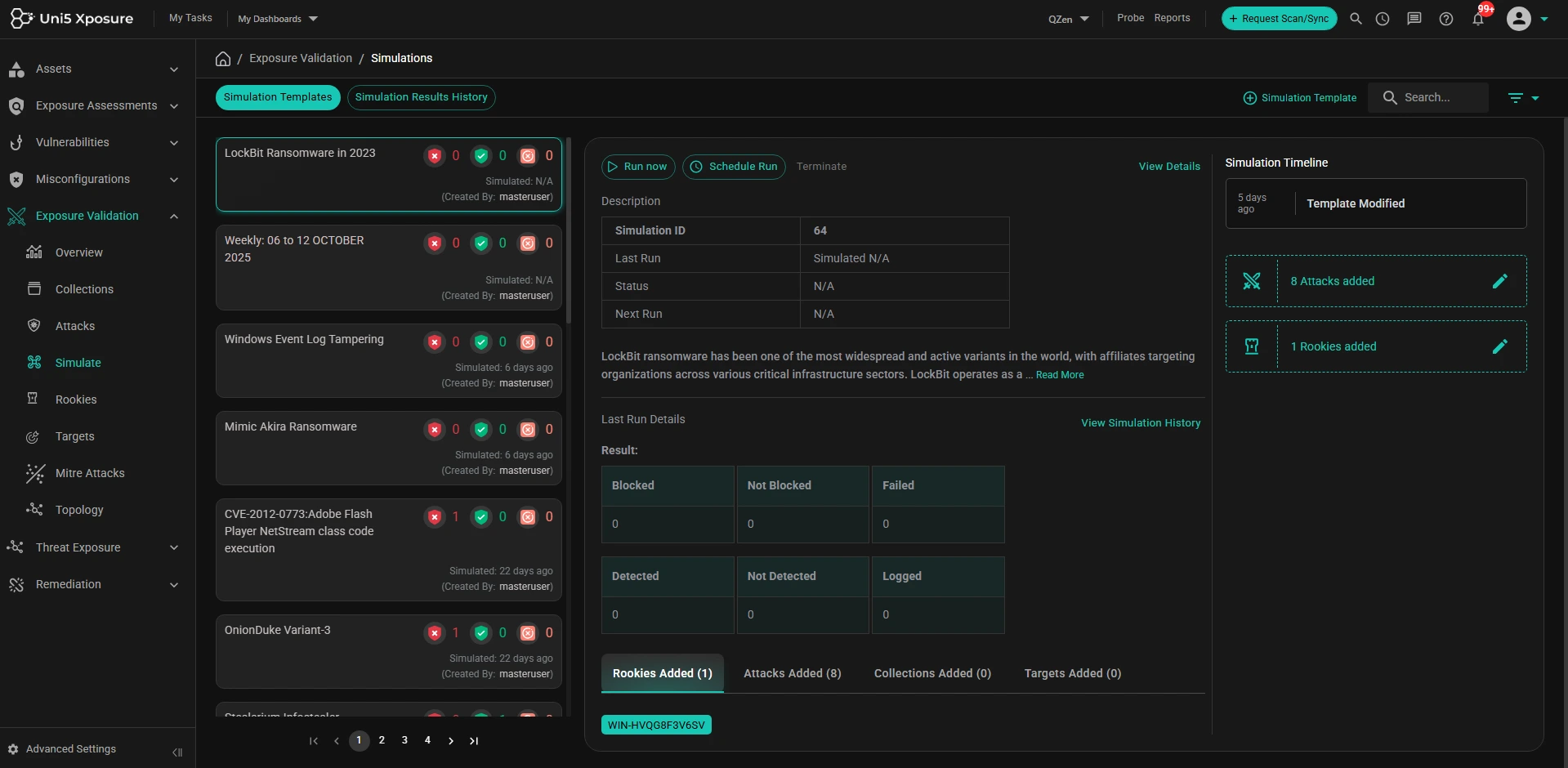
Safely validate security controls to ensure they are working as expected. Simulate attacks before threat actors do.
1-click risk reduction with automated remediation workflows. Turn insights into action instantly.
Define and manage your attack surface scope across all assets. Know what you need to protect.
Filter by severity
Real-world risks
Critical assets
Confirmed exploits
.svg)
.svg)

Consolidate findings from multiple scanners in one platform. See and evaluate risk across the attack surface in one view.
Easy and dynamic prioritization of vulnerabilities based on risk and exposure.
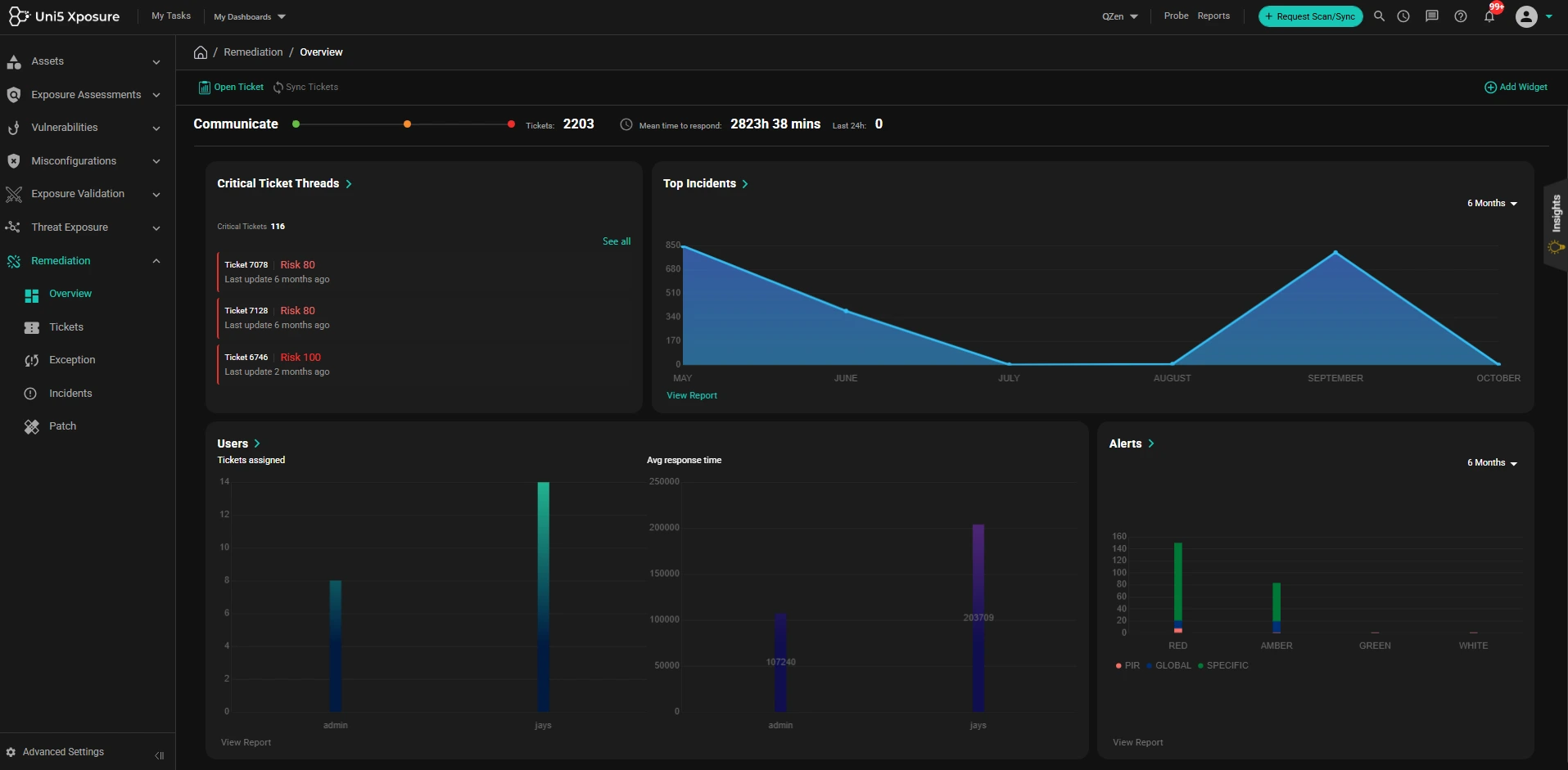
Remediating vulnerabilities to fix the exposures and risks to increase cyber resilience against attacks. Security controls are validated and improved.
Fix less, secure more with low efforts yield maximum ROI and higher efficacy.
.svg)
Consolidate findings from multiple scanners in one
platform. See and evaluate the attack
surface in one view.
.svg)
Prioritization based on your business context. Easy and dynamic prioritization of vulnerabilities based on risk and exposure.
.svg)
Remediating vulnerabilities to fix the exposures and risks to increase cyber resilience against attacks. Security controls are validated and improved.
.svg)
1-Click risk reduction by pushing IOCs to your security controls for threats that are possible in your environment.
.svg)
Fix less, secure more with low efforts; yield maximum ROI and higher efficacy.
Reduction in vulnerabilities to fix
To identify the top 1% risks
Unified view across all scanners

For Exposure
Assessment Platforms
2025
Exposure Assessment Platform
2024, 2025
Worldwide Exposure Management
Q3, 2023
Gartner® Magic Quadrant™
4.9/5
Pinpoint your most notorious vulnerabilities and risks in minutes, not days, with the Hive Pro platform. Now powered by Arbis AI.